皆さんはUnicodeの闇をどこまで知っているだろうか・・・
自分もそんなには知らないが、今回は思った以上に沼だった『書記素分割』について紹介していこうと思う。もはやうろ覚えだが詳細は他の人の記事にお任せする👻
そもそもUnicodeとは
まずUnicodeのざっくりした紹介からしていこうと思う。と言いつついきなりリンクをぺとり。
元々コンピューター上の文字はアルファベットだけで始まったが、コンピューターが世界中に普及して、異なる言語文化圏同士でのやり取りも増えていく中で後付け仕様が膨らんでいた当時の文字コードに限界を感じた人々が文字コードの世界統一規格を作ろうと立ち上がったのが始まりということだと思う。多分
3つのエンコード
Unicodeの最小単位ともいえるのがコードポイントである。コードポイントは21bitの数値で1つの文字に対応している。つまり端的に言ってしまえばUnicodeとは「1文字が21bitな文字コード」ということなのだが、そんな中途半端なビット数をどう格納しているのだろうか?
Unicodeには3つのエンコード方式が存在する。UTF-32,UTF-16,UTF-8だ。それぞれ後ろについている数字がエンコード後のビット数を表す。
UTF-32は21bitをそのまま32bitに拡張するだけのエンコード方式だ。一番単純だが1文字4バイトなので無駄が多く、通常は保存するデータに使用されることはない。
UTF-16は2バイト単位で格納する。当初のUnicodeとはUTF-16のことだったのだが、全ての文字が16bitに収まらなかったためエンコード方式が3種類に増えてしまったらしい。ある意味一番存在意義が無いエンコード方式と言える。UTF-16では16bitからあふれた文字をサロゲートペアと呼ばれるニコイチ表現で定義しているため、1文字が2バイトもしくは4バイトとなる。
UTF-8はちょっと複雑だが一番実用性が高い。1つの文字を1~4バイトで表現するのだが以下のように1バイト目の値で何バイト文字か分かるようになっている。
- 192未満なら1byteで1コードポイント
- 224未満なら2byteで1コードポイント
- 240未満なら3byteで1コードポイント
- それ以外なら4byteで1コードポイント
ASCIIコードの範囲の文字しか使わなければ1文字1バイトで済むのでかなり効率的である。
書記素クラスター
世界中の文字をエンコードするのにこれだけのルールで済むなら悪くないだろう。しかし、そうは問屋が卸さない。なんとコードポイント同士も合体することがあるのだ。それが書記素クラスターと呼ばれるものである。
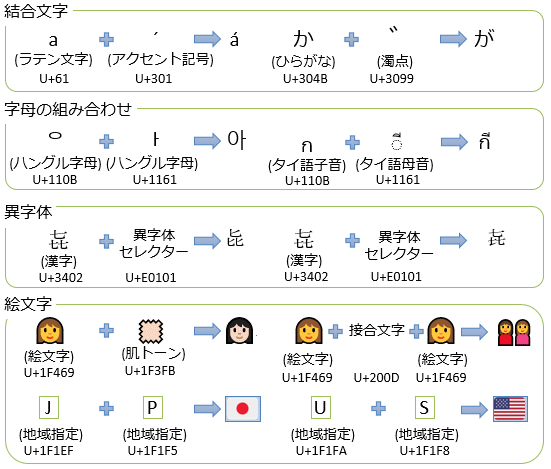
書記素クラスターの利点は、限られたコードポイント空間の節約だと思われる。例えば肌トーンと呼ばれる絵文字があるが、これは「肌を含む絵文字」の直後に配置することによって直前の絵文字と合体し肌の色を変更するという機能がある。これによって「肌を含む絵文字」×「肌色バリエーション」個の組み合わせだけ必要な絵文字を「肌を含む絵文字」+「肌色バリエーション」個に抑えることができる。「肌を含む絵文字」も「肌色バリエーション」も今後増えることを考えると書記素クラスターの合体仕様は必須に思える。一方で、「ひらがな+濁点=濁点付き文字」になる仕様や「ハングル文字をパーツ連結で表現」する仕様においては疑問がある。なぜならこれらはバラバラのパーツも合体後の文字もコードポイントが割り当てられているので、むしろコードポイントを無駄に浪費しているとしか思えないからだ。目的がコードポイント空間の節約でないならそれでも良いとは思うが、なんというか「文字と文字を合体させて別の文字が作れる」という仕様で遊んでるだけなんじゃないのと言いたくなるような文字がちらほらある。
――この辺にややイラっとしたのは次で紹介する書記素分割の処理が非常に面倒だったからである。実装しながら何度も「これ要る?」と思わされたのだ。
書記素分割
ではここから本題の書記素分割を実装していく。エンコードはUTF-8とする。
UTF-8からコードポイントへのデコードに関しては1バイトずつデータを見て変換するだけなので実装上問題ない。しかし、書記素クラスターの連結ルールに関してはそんなスマートな仕様は無く、ユニコードコンソーシアムが公開しているデータベースを元にハードコードで実装しなくてはならない。
それがこれである。
https://www.unicode.org/Public/15.0.0/ucd/auxiliary/GraphemeBreakProperty.txt
デデドン!!(絶望)
なんだこれは、たまげたなぁ・・・
なんと書記素を正確に取り出すにはDB検索をして力技で判定を行う必要があるらしい。しかもこのルール、Unicodeのバージョンによってどんどん更新されており新バージョンが出るたびに実装し直しが必要なのだ。この辺のことを記事にした先人の方がいらっしゃるのでぺとり。
上記ではUnicode12.0.0の実装が行われていたが、自分が実装した時は既にUnicode14.0.0が出ていたので上記を参考にしつつ14.0.0で同様の実装を行った。しかし、12.0.0と14.0.0では結構ルールもデータベーステキストの形式も異なっており公式の英語ドキュメントを読み漁る必要があったので大分しんどかった・・・。
先人の実装を参考に作ってみた結果がこちら↓
c++版(クリックで展開)
凄まじく長い判定関数・・・。えぐすぎるだろ!もちろん手書きではなく公式のDBを元に自動生成している。
c++版はc++20のコルーチンを利用して連結判定のステートマシンを実装した。公式でもステートマシンで実装するといい感じヨと書いていたので、めったにないc++コルーチンの使いどころやんけ!とウッキウキで実装した*1。ちなみにこれ↑このままじゃコンパイル通らないので使いたい場合は足りないヘッダや名前空間の付与など各自でお願いします。
c#版(クリックで展開)
コード生成はC#で書いたのでついでにC#実装も載せる。こちらもコルーチンでステートマシンを実装。
これで正しく文字描画が出来るぞ👍🏻
結局なんでこんな大変な思いをして書記素分割を実装してきたかというとゲームでユーザー入力の文字に含まれる絵文字などを正しく表示するためである。実はアカシックエンジンのラベルは書記素分割をやっていないので一部の文字で表示が崩れてしまう。

![]() 」をアカシックエンジンのラベルと自前のラベルで比較したものである。左上がアカシックで右下が自前のもの。アカシックはそもそも色が付いていないという話もあるが、重要なのはそこではなく、2文字に分離してしまっていることである。
」をアカシックエンジンのラベルと自前のラベルで比較したものである。左上がアカシックで右下が自前のもの。アカシックはそもそも色が付いていないという話もあるが、重要なのはそこではなく、2文字に分離してしまっていることである。![]() この絵文字はコードポイント的には2文字で構成されており、アカシックはコードポイント単位でしか文字を認識しないためこのような描画になってしまうのだ。これを正しく描画するには2文字まとめてキャンバス2DのfillText()に渡す必要がある。
この絵文字はコードポイント的には2文字で構成されており、アカシックはコードポイント単位でしか文字を認識しないためこのような描画になってしまうのだ。これを正しく描画するには2文字まとめてキャンバス2DのfillText()に渡す必要がある。
ちなみになぜアカシックエンジンがわざわざ1文字ずつfillText()しているかというと、DynamicFontのテクスチャアトラスにレンダリング結果をキャッシュするためだ。UnityのTextMeshProなんかでもそのようにしている。
文字のレンダリングというのは結構重い。数十点~数百点の制御点からなるベクター画像のレンダリングに他ならないからだ。そんな重い処理を頻繁に行っていてはゲームの邪魔をしてしまう。そこで、巨大なテクスチャにレンダリング結果を詰め込んでおいて、次回以降はそのテクスチャの部分描画によって文字の表示をすることでかなりの軽量化になる。まぁその辺の実装めんどいので毎回文字をレンダリングしてるゲームも多いだろうが、アカシックは割とちゃんとしてるので1文字ずつキャッシュしている。しかし、書記素分割まではやってないために絵文字の分離という問題が起きてしまったのだ。*2
ゲームにおける動的な文字描画に関しては別記事でまとめるつもりだが、今回はそれを実現する上で書記素分割まで実装しているとより見た目が良くなるよというお話でした。