前回まででWebGLを使い始めるところまで行った。
あとは普通にWebGLを駆使して作ってけばいいだけなので公式リファレンスや色々な解説サイトなどを参考に作ってください。で終わりなのだが、さすがにそれだけでは味気ないので自分が作って行く中で気づいた点などをちらほら書いていこうと思う。
まずは描画の最適化について。
描画のボトルネックを知る
WebGLなどのハードウェア支援で描画する際にパフォーマンス上のボトルネックになる要素は何なのか?もちろんGPU処理自体が重ければフレームレートは落ちるが、他にも、というか割と多くの場面でCPU負荷でフレームレートが下がっていることも多い。というのも、GPUにコマンドなどを送る処理というのは結構重いらしく、大量の表示物があるとGPU的には余裕でもCPUが先に限界になってしまうというのだ。
そこでWebGL2.0からはコマンド転送量を減らすことのできる機能がいろいろ使えるようになっているので、その辺をしっかり活用してできるだけ処理を軽くしよう。ただし、その分動かないブラウザがやや出てくるので多少のバグ報告は来るだろうが諦めよう。
というわけでここからは3D描画システムを作るうえで押さえたいポイントを紹介していく。
CPU最適化機能
1.UBO
もともとOpenGLでシェーダー変数の値を設定するにはパラメータごとに転送関数を呼び出す必要があった。しかも前回の値を使い回すこともできないため*1、ほぼ毎回再設定が必要。そのため毎フレーム「オブジェクト数*パラメータ数」分glUniform1fなどの設定関数を呼び出すことになる。複雑なマテリアルになれば当然パラメータもどんどん増えるので爆発的に関数呼び出しが増えそうというのは想像できるだろう。そしてこの大量の呼び出しがかなりのCPUボトルネックになってしまう。
そこでUBOを使うと何ができるかというと、これらのパラメータ設定を1個にまとめることができる上に使いまわすことができるのだ。例えば以下のシェーダー変数がある時に
mat4 world; mat4 viewProj; vec4 color;
UBOなしだと描画ごとに3回ずつパラメータ設定を呼び出す必要があるが、UBOありならば1回で済むし、何なら前フレームと値が同じ場合は0回で済む。ざっくり言えば毎フレームのパラメータ設定を「オブジェクト数」以下に抑えることができるのだ。これはCPU負荷をめちゃくちゃ軽減できるので例えシェーダーの変数が1つでもやった方がいいだろう。
2.VAO
これはもう上記URLの内容をしっかり読んでいただければそれでよいのだが、、、簡単に言うと「ポリゴンを描画する際どんな頂点情報を送るかブラウザに教えるための煩雑な手続きを一括で処理できるようにしたもの。」である。WebGL2.0では描画するポリゴンの頂点情報を結構柔軟に設定できる。
- 頂点バッファありか無しか、使うならどのバッファを使うか
- インデックスバッファありか無しか、使うならどのバッファを使うか
- 頂点のデータの並びはどんなか
- など・・・
柔軟な分設定項目が多く、ポリゴンを描く前にいちいちこれらの設定をしないといけないのが非常にCPUボトルネックを生み出していた。しかしなにかオブジェクトを描くにあたって毎フレームこれらの設定が変わるということはまずないため、最初に1回設定したら後は同じ設定を使いまわすのが正道だろう。それを実現するのがVAOであり、これも全てのポリゴン描画で使うべきといえる。
3.インスタンシング
同じポリゴンを大量に描画したい時、素直にやるなら単純にその数だけ描画すればよいのだがその数が数千~数万などになってくるととてもじゃないがCPU処理が間に合わない。そこで、通常の描画関数の代わりにインスタンシング版の関数を呼び出し、シェーダーなどもインスタンシング用に書き換えることで数千回分の描画を1回の関数呼び出しで行うことができるようになる。ちなみにこれで削減できるのはCPU負荷でありGPU負荷はほぼ変わらない。
例:ドロー関数をインスタンシング用に
glDrawArrays() → glDrawArraysInstanced()
in vec3 pos;
uniform mat4 wvp;
void main(void) {
gl_Position = vec4(pos, 1.0) * wvp;
}
↓シェーダーをインスタンシング用に
in vec3 pos;
uniform mat4 wvp[256];
void main(void) {
gl_Position = vec4(pos, 1.0) * wvp[gl_InstanceID];
}
ちなみに
3D迷路(仮)という実験用に作っていたゲームでは129*129=16641マスに対して立方体ポリゴンの壁と床を1個ずつ配置するという方法でシーンを構築していた。 壁8000個超、床16000個超でしかも、深度パス・カラーパス・シャドウパスの3回描画していたのでそれぞれ3倍になるのだが、ドローコールは確か20~30くらいで済んでいた。これだけのポリゴンを毎フレーム描画してもスマホで60fps近いフレームレートが出せていたのは間違いなくインスタンシングの力が最もデカかっただろう。
ここまでで紹介した3つのテクニックはどれもオプションであり、これらを使わなくても同じ描画結果は出せる。しかし、使えるならできるだけ使うべき機能たちなので描画システムを設計するときには最初からこれらを織り込み済みで設計した方が後々楽である。
まぁなぜオプションなのかといえばサポートしていない環境も存在するからという話でもあるので本来は使えるかどうかチェックして、使える時だけこれらのテクニックをONにするというのが正式な対応なのだが、これらはどれもパフォーマンス上めちゃくちゃ重要であり、これらが使えないならそもそもまともな速度で動かないことも多いので、そこまでして広い環境をサポートするくらいなら動く環境だけサポートでもいいんじゃないのというのが個人的な感想です。
GPU最適化テク
以下はCPU負荷を抑えるわけではないがGPUに結構効くテクニック集。こっちも大事よね。
1.Early-Z pass
3Dのオブジェクトを描画する際、普通はカラーバッファに加えて深度バッファにも書き込む。これがあると同じピクセルに手前のものを描画した後奥のものを描画しようとしても、書き込めないようにしてくれるので描画順に関わらず見た目の奥行きが正しくなるのだ。(図解が多くてわかりやすい解説があったので貼っておく)
さらに頂点シェーダーを実行したあとラスタライズというどのピクセルに書き込むか算出する処理を経てピクセルシェーダーが呼び出されるのだが、どうせ深度バッファで弾かれるならピクセルシェーダーの呼び出し前に弾いたほうがいいよねということで、Early-Z Culling(Early Fragment Test)という最適化処理がGPUに実装されている*2。 下図で言うとtesting and blendingが通常の深度テストタイミングなのだが、Early-Zがサポートされているとfragment shaderのところでテストされる*3。
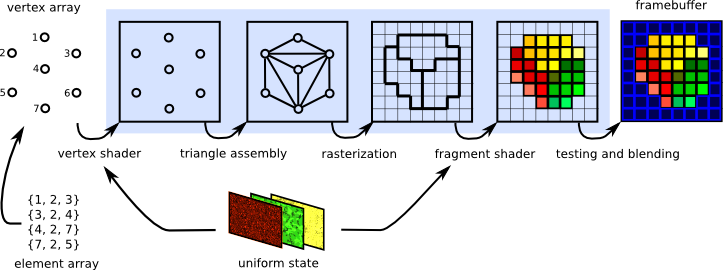 画像引用元:https://graphicscompendium.com/intro/01-graphics-pipeline
画像引用元:https://graphicscompendium.com/intro/01-graphics-pipeline
これを利用した最適化手法がEarly-Z passである。手法の内容は簡単で通常描画の前にシーン全体の深度だけを書き込むパスを追加するというものだ。
深度だけ書き込むにはどうするのかというとピクセルシェーダーを設定しないで描画するだけで良い。この描画では一切ピクセルシェーダーが呼び出されないので高速に実行できる。
次にglDepthFuncにGL_EQUALを設定して通常描画を行う。こうするとシーンの最前面、つまり見えるピクセルのみ深度テストに合格するようになるので、ピクセルシェーダーの呼び出しが最小限となるのだ。
ここまで読んでみて、「シーンの描画が2倍に増えてるじゃん。ほんとに速くなんの?」と思った方もいるだろう。そう、この手法が効果的な場面にはいくつか条件がある。まず、ドローコールが倍に増えるのでそもそもドローコールを抑える工夫ができている必要がある。それは前半に書いたような最適化やフラスタムカリングを行えば良い。 次にピクセルシェーダーが重く、しかもオブジェクト同士が何重にも重なるシーンであること。この手法で回避できるのは重複したピクセルシェーダーの実行なのでそもそもピクセルシェーダーが激軽だったら効果は薄いし、オブジェクトの重なりが少なければ重複ピクセルも少ないのでこれもまた効果は薄くなる。 次に超ハイポリモデルでないことだ。頂点シェーダーは普通に2倍実行されるため単純に頂点シェーダーが重いと逆効果になる可能性がある。 あと、当然だが深度バッファに書き込みを行うので半透明オブジェクトには適用出来ない。
これらの条件を満たすシーンであればこの手法は結構強力なのでやるべきだろう。
おまけ
自作ゲームでいうと怖い部屋3Dでは壁がかなり重なるのでこのテクを使っているが、ニコニコ迷宮では壁を取っ払ったせいでほぼ効果がないので使っていなかったりする。 上図は怖い部屋3Dの描画結果。下図は同じシーンのポリゴンの重なりを可視化したもの。明るいところほど重複した描画が発生していることを表している。これらのピクセル数分だけシェーダー処理が省けるのだからかなりの効果があると言える。逆にこうならないのが分かっているゲームならこのテクは特に不要である。


2.Z sort
上に書いたように深度テストでいかにピクセルシェーダーの不要な実行を避けるのが大事なことかわかったと思うが、他にも素朴なやり方で減らす方法がある。それがZ sortだ。
これはシーンを描画する前に全オブジェクトを奥行き順にソートしてから描画しようというもので、手前のものから先に描画していけばそれだけ深度テストに失敗するピクセルが増えるというのは直感的にもわかりやすいだろう。さっきはカラーバッファへの書き込みにだけ言及していたが当然深度バッファへの書き込みも減らせるに越したことはない。手前から描くことで深度バッファへの書き込みを減らせるというわけだ。また、パフォーマンスとは関係なく半透明オブジェクトを正しく描画するためには奥から順に描く必要があるので半透明と不透明で描画処理をしっかり分けることが重要だ。
このように描画周りの処理の設計への影響が大きいので最初からこの辺を意識して設計しておくとよい。
3.レンダーステート
レンダーステートとはglBlendFuncやglCullFaceやglDepthFuncなどのハードコードされた描画処理を制御する各種設定のことである。これらは地味なところではあるが、適切な設定をすることでより負荷を減らすことにもつながる大事な要素である。基本的には実現したい描画のために設定を行う(加算モードで描画したいとか奥行きを無視した描画がしたいとか)のだが、例えば、ブレンドモードが半透明描画用の設定になっている状態で完全不透明なオブジェクトを描画した場合、正しい描画結果自体は得られる。しかし、本来不要なブレンド計算が描画した全ピクセルに対して実行されてしまい余計なGPU負荷が発生する。であればブレンドモードをオフ(glDisable(GL_BLEND))にして描画する方が、同じ結果でGPU負荷が少なくなるのでよりベターだ。
このようにレンダーステートは欲しい結果が得られてかつGPU負荷を減らせるように細かく設定していくのが大事である。レンダーステートの設定もGPUコマンドの生成であるためCPU負荷はややかかるが、その設定1つで数十万ピクセルの無駄なGPU処理を減らせるので時には払うべきコストだろう。
描画最適化の話題でよく出てくるフラスタムカリングやZソートだが実は今のところ自作のゲームでは採用していない。実はこれらはCPUで結構な計算負荷が発生するためできればやりたくないのだ。オープンワールドゲームみたいに超広範囲に不規則にオブジェクトが大量におかれてたりしない限りは他の最適化手法だけで大体事足りるので意外と優先度が低いと思っている。迷路ゲームだって真面目にフラスタムカリングしようと思ったらCPUで数千個~数万個のオブジェクトに対して判定を行う必要がある(まぁほんとはもう少し最適化できるのだが・・・)。マルチスレッドも使えない環境ではこれらの負荷はかなりきついので、安易に実装しても余り意味はないかも。
まとめ
今回紹介した内容は最適化手法の内のごく一部に過ぎない。実際自作ゲームではこれ以外にもいくつかの最適化を行っているが、あまり汎用的でないものも多いので紹介は省いた。実装コストと改善するパフォーマンスでみてコスパが良さそうなものを抜粋したので、この辺を優先して実装するだけでも結構パフォーマンス改善するのではないかと思う。